Logs Die With Your Cluster: How AWS Events Helped Us Build Real Resilience
We often talk about resilience in the cloud. Our systems are wired with retries, backoffs, dashboards, and alerting pipelines. But one lesson I learned the hard way: resilience stops working the moment your resource disappears.
Recently, we had an EMR cluster running heavy ETL jobs — reading from Trino tables, writing downstream to Elasticsearch. We had all the cushions in place: retries on every stage, Datadog metrics, structured logs. Everything looked resilient on paper.
Until one day, the cluster itself failed. Not a job error. Not a transient read timeout. The whole resource was gone. And with it, so were the logs, retries, and every other safeguard baked into the application layer.
That was the “aha moment.”
Where AWS Events Changed the Game
What saved us wasn’t retries or log analysis — it was AWS events.
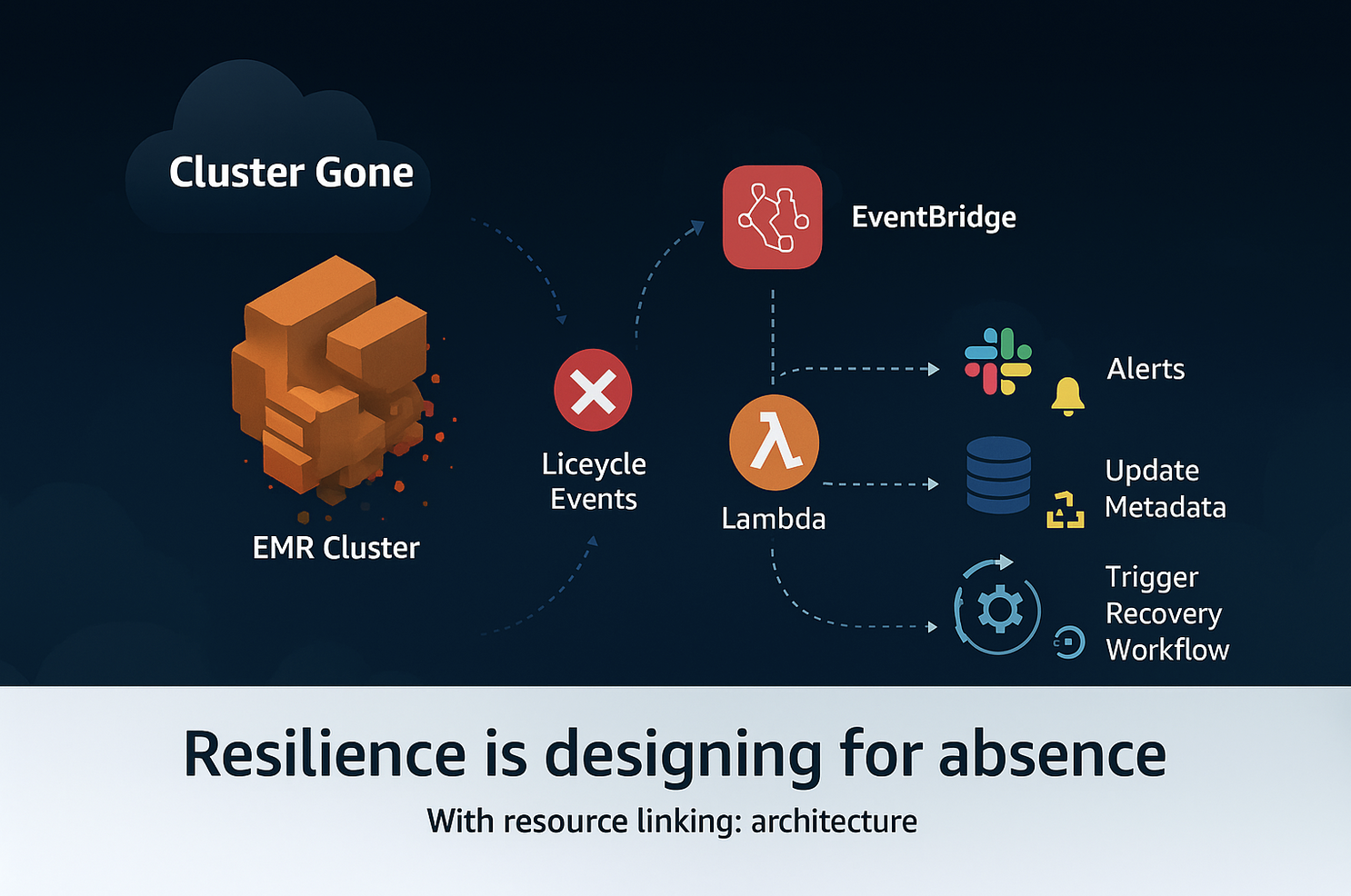
We hooked into EMR lifecycle events:
ClusterRunningClusterTerminatedClusterTerminatedWithErrors
Each of these emitted an event into EventBridge, enriched with cluster metadata and tags we had added earlier (critical for filtering which events mattered). From there, a Lambda subscriber would capture the state and perform decoupled actions:
Sending alerts with context.
Updating downstream systems so they weren’t left in limbo.
Triggering compensating workflows.
This event-based safety net gave us infrastructure-level resilience, not just application-level resilience.
Architecture Snapshot
Here’s the high-level flow we implemented

Why This Matters (SRE Lens)
In Google’s SRE book, a small quote stuck with me:
“Hope is not a strategy. Systems must be designed to expect and tolerate failure.”
We usually design for application failure modes. But events let you design for infrastructure failure modes. Logs vanish when clusters terminate, but events outlive the resource.
That separation made all the difference for us. Instead of reactive firefighting, we now have decoupled responders that act the moment AWS emits a resource signal.
Takeaway
Resilience is not just about keeping jobs alive. It’s about keeping the system aware even when resources die. AWS events — when combined with EventBridge, tagging discipline, and automation — can turn your cloud into a self-healing nervous system.
If you’re building ETL pipelines, analytics jobs, or any workload that depends on ephemeral clusters, don’t just rely on retries and logs. Capture the lifecycle events.
Because when the cluster is gone, your only lifeline is the signal AWS sends on its way out.